Soyutlama Katmanları, Arayüzler ve Standart C Kütüphanesi¶
Bilgisayar sistemleri (bilgisayarların kendisi, bilgisayarlar arası ağlar gibi), çeşitli teknolojiler ile oluşturulan çözümlerin üst üste konulması ile oluşturulur. Bu Çözüm Yığını (Solution Stack) içerisindeki her bir katman, bir alttaki katmanın detayını bilmez fakat sunduğu çözümü arayüzler (interfaces) ile kullanır. Yapılan bu soyutlama sayesinde çözümler birbirleriyle hızlı bir şekilde entegre edilebilmekte ve geliştiricilerin çözüme varma hızı artmaktadır. Elbette çok katmanlı ve çok soyutlamalı çözümler genellikle bellek tüketimi ya da CPU zamanı gibi çeşitli açılardan katmansız ve soyutlama içermeyen tek blok (monolith) çözümlere göre daha verimsiz olmaktadır. Fakat günümüzde birçok alanda katmanlı ve soyutlamalı yapının getirdiği geliştirici verimi artışı (daha hızlı ve hatasız kod yazma gibi), oluşan performans verimsizliği ile kıyaslanamayacak kadar fazladır. İşlemcilerin hızlanması, belleklerin ucuzlaması ve maliyetlerinin düşmesi oluşan performans verimsizliklerini iyice göz ardı edilebilir seviyeye çekmektedir.
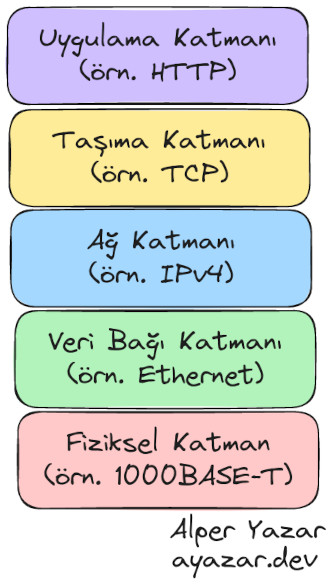
Kullandığımız Internet sistemi soyutlamaya en iyi örneklerden biridir.¶
Bilgisayarlar arasında kullandığımız veri değişim ve iletişim protokolleri soyutlamanın en iyi çalıştığı örneklerden biridir. Bunların başında ise İnternet gelir. Biz bir web sitesine girdiğimiz zaman tarayıcı yazılımımız ile web sunucusu yazılımı sanki aynı bilgisayar üzerinde çalışıyormuş gibi birbirleriyle haberleşip bir veri aktarımız gerçekleştirirler. Halbuki bu iki yazılım, iki farklı bilgisayar üzerinde, Dünya’nın herhangi bir iki noktasında (belki de başka gezegenler üzerinde) olabilir. Bu yazının konusu, İnternet protokolü olmadığı için detaylara girmiyorum fakat bu protokollerin birbiri üzerinde nasıl çalıştığını aslında günlük yaşantımızda gözlemliyoruz. Örneğin bizlerin klasik internet dediği şey, yani bir web sitesine girip yazı ya da video bir içerik görüntüleme işi, HTTP protokolü üzerinde çalışmaktadır. Çizimde de en yukarıda bulunan Uygulama Katmanı, bu protokoldür. Biz bir internet sitesine girdiğimizde kablolu Ethernet üzerinden mi bağlıyız? Wi-Fi ile mi bağlıyız? cep telefonunda ise mobil veri mi kullanıyoruz? Ya da işin biraz daha teknik kısmını biliyorsak IPv4 mü yoksa IPv6 mı kullanıyoruz? diye hiç düşünmüyoruz. Bu protokoller birbirleri üzerinde çalışıyorlar, bir katmanın sunduğu çözümü başka bir katman o çözümün detayını bilmeden kullanıyor. O yüzdendir ki ileride 5G, 6G gibi teknolojilerle alt katmanlarda ciddi değişiklikler olsa da en tepede çalışan Uygulama Katmanı bundan pek etiklenmeyecek ve internet tarayıcımız HTTP çalışmaya devam edecek. Bu konuyu fazla uzatmadan burada kesiyorum. Elbette protokol seviyesindeki bu soyutlamanın da getirdiği verimsizlikler oluyor, örneğin haberleşme bant genişliğinin hepsi faydalı veriye gitmiyor. Fakat insanlık bu problemi, soyutlama katmanları ile daha küçük parçalara bölüp, bu problemleri ayrı ayrı çözüp daha sonra birleştirip büyük çözümü oluşturduğu için bugün İnternet gibi devasa altyapı olabiliyor.
Soyutlama her yerde var. Sadece bilgisayarlar arası protokllerde değil bilgisayarın içinde bile birçok soyutlama katmanı mevcut. Programcı tarafından soyutlamanın başladığı ilk yer işlemciler yani CPU’lar. İşlemci tasarlayanlar işlemcinin detaylarını ve iç yapısını Instruction Set Architecture (ISA), Buyruk Kümesi Mimarisi ile biz programcılardan gizliyorlar. Bu iyi bir şey, çünkü programcılar işlemcilerin detaylarını bilmek zorunda kalmadan (ya da ne kadar bilmek isterlerse) programlarını yazabiliyorlar. Bu sayede bizler de bilgisayarımızı alırken içerisinde Intel işlemci mi AMD işlemci mi var diye pek düşünmüyoruz, çünkü ikisi de aynı ISA’yı destekliyor. ISA’yı kullanarak program yazma pratiğine de zaten assembly programlama diyoruz. Sadece 0 ve 1’lerden oluşan makine dilini saymazsak (ki zaten assembly programlama bunun çok üzerinde değil) pratikte kullanabileceğimiz en düşük seviye dil assembly olmaktadır. Assembly bazı Türkçe kaynaklarda sembolik makine dili olarak da geçmektedir.
Yapılacaklar
Add “Why do we have programming langauges part 1” when ready
Yazılımcı açısından bilgisayar içerisindeki en belirgin soyutlama katmanı belki de İşletim Sistemi, Operating System (OS) olmaktadır. İşletm sistemleri bilgisayarın donanımını programıcdan soyutlayarak programcıya işlemci, bellek gibi birçok açıdan ilüzyon yaratırlar. Yazılımcılar, yazdıkların kodun çalıştığı bilgisayarın detaylarını bilmeden bu sayede program yazabilirler. Fakat bir problem var. Gerektiği durumlarda donanım ile nasıl konuşacağız? İşletim sistemi üzerinde çalışan programlar, donanıma (yani donanım yazmaçlarına, register) çoğu zaman doğrudan erişemezler. Bunun dışında tipik olarak başka programlara da pek karışamazlar. Peki bir ihtiyaç durumunda bu nasıl olacak? İşte burada programlar, işletim sisteminden yardım alırlar. Bir programın üzerinde çalıştığı işletim sistemi ile iletişime geçmesinin ve ondan bir şey istemesinin yolu system call yani sistem çağrılarını kullanmaktadır. Örneğin Linux üzerinde sistem programlama yaparken de ilerleyen kısımlarda kernelden sistem çağrıları bir şeyler isteyeceğiz fakat bunu kernelin iç yapısını neredeyse hiç bilmeden yapabileceğiz. İşte bu da bizler için bir soyutlama katmanı olmaktadır. Kernel bizler için bir arayüz oluşturmakta, bizler de kernelin iç detaylarını bilmeden bu arayüz üzerinden kernelden faydalanabilmekteyiz.
Linux kerneli, 300’den fazla farklı sistem çağrısı desteklemektedir. [1] Bu sayı ilk bakışta çok olabilir fakat Windows’un binlerce sistem çağrısı desteklediğini okumuştum. Bu yüzden Linux’tan, minimal düzeyde sistem çağrısı sunan bir işletim sistemi olarak bahsediliyor. Daha az sistem çağrısı, sistem programlama yapacak kişi tarafından öğrenilmesi gereken daha az fonksiyon demek. Bu sistem çağrıları syscall olarak da geçmektedir.
Sistem çağrısı mekanizmasının donanım üzerinde nasıl gerçekleştirdiği konumuz değil, en azından bu yazı kapsamında. Fakat kabaca şöyle: Burada işlemcinin registerları yani yazmaçları kullanılıyor. Sistem çağrısı yapan program, işlemcinin belirli yazmaçlarına belirli değerler yerleştiriyor. Her bir sistem çağrısının aslında bir numarası var. Bunu kullanmak isteyen programcı, o numarayı bir register’a yazıyor. Bir parametre geçirecekse (fonksiyonlar ile geçen parametreler gibi düşünebilirsiniz) o parametreleri de diğer yazmaçlara dolduruyor ve sistem çağrısı yapıyor. Kernel ise bu yazmaçların değerini okuyarak programcının gerçekleştirmek istediği işi (izni var ise) yapıyor ve geri dönüyor. Bu esnada işlemci de mod değiştirmiş oluyor (user mode ve kernel mode). Fakat bu yazıda o detaylara girmek istemiyorum. Aklımızda kalması gereken şey, işletim sistemi çekirdeğinin bir şekilde programcılara kullanabilecekleri bir arayüz sunması ve bu programcıların bu arayüzü kullanarak çekirdeğin iç yapısının detayını bilmeden bundan faydalanabiliyor olduğu.
Peki bir şey dikkatinizi çekti mi? Kernel ile konuşup, ondan bir şey isteyen bir
program bu isteğini CPU’nun register’larına çeşitli değerler koyuyor ve kernelin
bu değerlere bakarak çalışmasını istiyor. Bu sistemin sağlıklı çalışabilmesi
için her iki tarafın da register’lara aynı anlamları yüklemesi lazım. Örneğin
sistem çağrısı yapan program, register 0 ı sistem numarasını iletmek için
kullanıyorsa kernel de bu register’ı sistem numarasını okumak için kullanmalı.
Yani her iki taraf da register’ların anlamları üzerinden önden bir anlaşmaya
varmalı. İşte burada aslında kernel geliştiricileri, programcılar için bir
arayüz tanımlıyorlar. Bu register şu anlamda, şu register bu anlamda diyorlar.
Buna calling convention adı veriliyor. Şu sayfada
Linux
kernelinin kullandığı calling convention’nun detaylarını görebilirsiniz.
System call’lardan kısaca syscall olarak da bahsediliyor.
Linux kernelinin oluşturduğu gibi iki farklı yazılımın birbiriyle uyumlu bir şekilde çalışması için oluşturulmuş, bu şekildeki düşük seviye arayüzlere Application Binary Interface (ABI) adı veriliyor. ABI kavramı sadece kernele özgü bir kavram değil. Daha genel olarak bir program bir fonksiyon diğerini çağırırken ne olacak? Register’lar ne anlama gelecek? Stack (yığıt) organizasyonu nasıl olacak? gibi sorular da ABI kapsamında yanıtlanıyor. ABI’nin önemli bir özelliği, derlenmiş program ve kütüphanelerin birbirleriyle uyumlu bir şekilde nasıl çalışacağını olabilecek en düşük seviyede tarifliyor olması. O yüzden binary arayüz olarak geçmektedir. ABI doğrudan programcılar tarafından kod yazılırken kullanılan “insanlar için tasarlanmış” arayüzler değillerdir.
Linux kerneli, ilk olarak 1991 yılında yayınlanmıştır. Günümüze gelen kadar kernel ciddi miktarda değişime uğramış ve gelişmiştir. Kernel geliştiricilerinin yıllar boyunca sabit tutmaya çalıştığı ve çaba harcadığı en önemli konulardan biri kernel tarafından sağlanan sistem çağrılarının ABI’larını sabit tutmaktır. Bu kararlı arayüz olmasaydı Linux kernel versiyon 5 üzerinde çalışan bir program, kernel 6 üzerinde çalışmayabilirdi. Bu da her bir yeni kernel yayınlandığında eldeki tüm programların kaynak kodundan yeni ABI için derlenmesini gerektirirdi. Bu, hiç kimsenin sürekli yapmak isteyeceği bir iş olmazdı. Ayrıca kaynak kodu elde olmayan, Linux üzerinde çalışan kapalı kaynak yazılımları idame etmek de ciddi bir problem olurdu. Eğer bir işletim sistemi, sunduğu arayüzde sürekli değişiklikler yaparsa bu işletim sistemi tarihin tozlu sayfalarına hızla karışır.
Belirttiğim gibi kernelin iç yapısı, kernelin içerisindeki fonksiyonlar çok ciddi değişikliklere uğradı. Fakat kernel, sağladığı arayüz ile kullanıcıdan soyutlandığı için bu değişiklikler kullanıcıları (neredeyse) hiç etikelemedi. Bu da aslında soyutlamanın bir önemini daha vurguluyor. Arayüzü bozmadığınız sürece içeride istediğiniz gibi değişiklikler yapabiliyorsunuz. Arayüz ile bir soyutlama yapılmasaydı, bu işler de bu kadar kolay olmazdı.
WE DO NOT BREAK USERSPACE! [2]
Linus Torvalds’ın (Linux’un yaratıcı) bir sözü [3]:
We care about user-space interfaces to an insane degree. We go to extreme lengths to maintain even badly designed or unintentional interfaces. Breaking user programs simply isn’t acceptable.
Yani diyor ki, kernelin arayüzünü bozmak kabul edilebilir bir şey değil. Var olan hatalı arayüzleri sıfr arayüzü bozmamak adına devam ettiriyoruz.
ABI şeklinde sağlanan kernel arayüzü birçok programcı için çok düşük seviye kalmaktadır. ABI’yı doğrudan kullanmak için temelde assembly dilinde programlar yazmamız gerekir, bu da kolay bir iş değil. Peki soyutlamayı biraz daha arttırabilir miyiz? İşte burada POSIX kavramı ile tanışıyoruz: Portable Operating System Interface yani Taşınabilir İşletim Sistemi Arayüzü. POSIX kavramına ileride değineceğim fakat bizlere sunduğu şey işletim sistemi ile C dili içerisinde, C fonksiyonları ile assembly seviyesine inmeden, konuşma imkanıdır. POSIX standartları ayrıca yazdığımız kodların sadece Linux üzerinde değil, Unix türevi diğer işletim sistemlerinde de (macOS gibi) çalışmasını sağlar. POSIX ile kernel bizden bir adım daha soyutlanmış olacaktır. Fakat hala kernele çok yakın bir noktadayız. İşte POSIX gibi çeşitli standartların ve kütüphanelerin, programcıların kaynak kodlarında C gibi görece yüksek seviye dillerde (assembly’e kıyasla) kullanması için sunduğu arayüzler ise birer Application Programming Interface (API) örneğidir.
Linux sistem programlamanın bir tanımı da kernel üzerinde C dilinde yazılmış POSIX fonksiyonları kullanarak program yazma eylemi olarak yapılabilir.
Standart C Kütüphanesi ve POSIX Fonksiyonları¶
Standart C kütüphanesi ve POSIX kütüphanesine amacı birbirine benzeyen
fonksiyonlar vardır. Örneğin open() bir POSIX fonksiyonudur ve standart C
kütüphanesinde bulunan fopen() ile benzer bir iş yapmaktadır. Peki farkları
nedir?
İlk olarak şunu tekrar hatırlayalım: C, herhangi bir işletim sistemine bağlı bir
değildir. Yani C dilinde Linux üzerinde de Windows üzerinde de program
yazabiliriz. Bu yüzden C standart kütüphanesinde bulunan fopen() fonksiyonu,
standartlarda belirtlidiği şekilde tüm işletim sistemleri üzerinde
çalışmaktadır. open() ise sadece Linux üzerinde çağrılabilecek bir POSIX
fonksiyonudur, Windows üzerinde bulunmamaktadır. Linux üzerinde çalışan bir C
kodunda fopen() çağrısı yaptığımız zaman bir süre sonra standart C kütüphanesi
tarafından open() çağrısı yapılır. Fakat Windows üzerinde aynı kodu
çalıştırdığımız zaman Windows API da tanılmanmış olan CreateFile (veya
benzeri) bir fonksiyon çağrılır. Standart C kütüphanesi bunu bizim için
halleder.
Eğer farklı işletim sistemleri üzerinde (Linux, Windows, macOS gibi) çalışacak kodlar yazmak istiyorsak, işletim sistemlerini bizler için soyutlayacak bir katmana daha ihtiyacımız vardır. Bu da tipik olarak programlama dilleri olmaktadır.
Daha Yüksek Seviyeli Diller¶
C, 70’li yıllardan gelen bir dildir. Yıllar içerisinde yazılım projelerinin karmaşıklığı artmış, software engineer gibi roller türemiş ve Agile 🫣 gibi yöntemler ortaya çıkmıştır. Bu değişimlerin temel amacı, karmaşıklığı sürekli artan yazılım problemlerine sistematik bir çözüm getirebilmektir. Günümüzde bulunan Python, JavaScript, PHP gibi dillere kıyasla C, düşük seviyeli dil kategorisinde kalmaktadır. Yeni diller, nesne yönelimli programlama (OOP) gibi yeni programlama paradigmalarını desteklemektedir. Bu sayede, bilgisayar donanımı daha fazla soyutlanabilmektedir. Bu tarz diller, bilgisayalarların iç yapısının modellenmesinden ziyade gerçek hayat problemlerinin bir programlama dili ile daha iyi modellenmesine uğraşmaktadır.
Bir dil ne kadar yüksek seviyeli olursa, donanımdan ne kadar uzak olursa olsun günün sonunda üzerinde çalıştığı işletim sisteminin çekirdeği ile iletişime geçecektir. Linux sistemler için kernel ile konuşmanın tek yolu syscall çağrılarıdır. Kod yazdığımız dil ne olursa olsun Linux syscall oluşturmak zorundadır (Windows için de Windows çağrıları). Diller doğrudan syscall yaparak veya Linux C API fonksiyonlarını çağırarak kernel ile iletişime geçerler.
Son olarak şunu da not etmek isterim ki bir dilin yüksek seviyeli olması, o dilin düşük seviyeli dillerden daha yetenekli olduğu anlamına gelmez. Programlama dili insan diline yaklaştıkça bilgisayardan daha çok soyutlanır, bu dillere yüksek seviyeli dil denir. Eğer dil makine diline daha yakın ise bu sefer de dil düşük seviyeli dil olur. Onun dışında bir üst-alt ilişkisi yoktur.
Özet¶
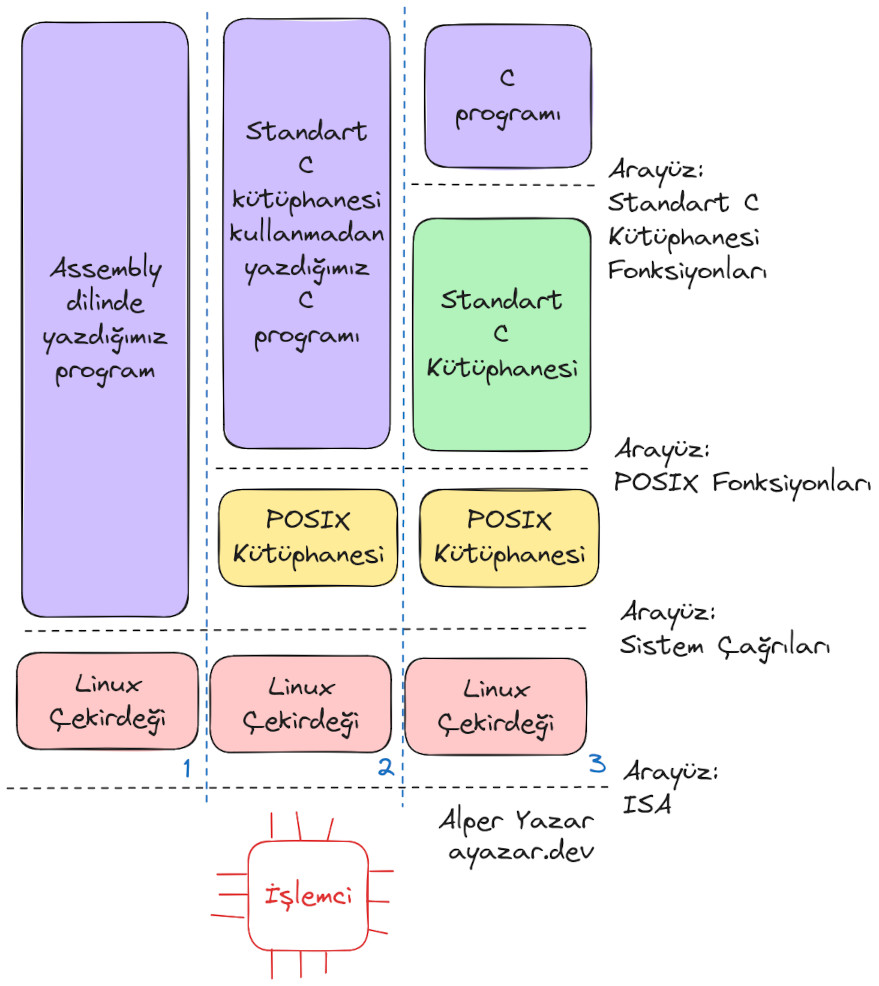
Linux üzerinde yazılım yazma alternatifleri¶
Çizimde de görülebileceği gibi Linux üzerinde çeşitli şekilde yazılım yazabiliriz. Burada en altta bulunan İşlemci bilgisayarın tüm donanımını tariflemektedir, yani sadece işlemci değil bellek, disk, ağ kartı gibi tüm donanımları düşünebiliriz. Linux gibi işletim sistemi çalıştıran bilgisayarlarda donanım tüm kontrolü işletim sistemi çekirdeğindedir. Bilgisayarda koşan diğer programlar kerneli (yani çekirdeği) by-pass geçemezler, işletim sistemi ile konuşurlar. İşletim sistemi gerekirse donanıma ulaşır. İşte bu yüzden işletim sistemi donanımın üzerindeki ilk katmandır.
1 Burada, Linux çekirdeğinde doğrudan ABI ile konuşuyoruz. Yani calling convention ile belirtilen, hangi registerda ne olması isteniyorsa onu Assembly dilinde yapıyoruz ve çekirdeğin fonksiyonlarını çağrıyoruz. Bu mümkün olsa da pratikte pek yapılan bir şey değil.
2 Burada, C dilinde kod yazıyoruz ama standart C kütüphanesini
kullanmıyoruz, doğrudan POSIX kütüphanesi ile bizlere sunulan ve kernelin
syscall’lerini neredeyse doğrudan yapan C fonksiyonlarını kullanıyoruz. Örneğin
dosya açmak için standart C kütüphanesinde fopen() fonksiyonu yerine open()
fonksiyonunu çağırıyoruz.
3 Bu ise en çok alışkın olduğumuz kodlama tarzı. C kütüphanesini kullanarak
kod yazıyoruz. Aynı örnekten devam edecek olursak open() kullanmıyoruz ve
fopen() kullanıyoruz. Sadece standart C fonksiyonlarını kullandığımız zaman,
standart C kütüphanesinin desteklendiği başka bir yere (örneğin Windows’a)
kodumuzu çok daha kolay taşıyabiliriz. 2 ve 1 nolu yöntemlerde ise aşağıdaki
işletim sistemine doğrudan bağlıyız.
Elbette sadece bu 3 yol ile sınırlı değiliz, hibrit bir şeyler de yapabiliriz. Örneğin yazdığımız bir C kodu hem standart C kütüphanesini kullanabilir hem de POSIX fonksiyonları ile çağrı yapabilir. Bu oldukça da yaygındır.
Peki hem standart C hem de POSIX fonksiyonları ile bir işi yapabiliyorsak hangi yolu kullanmalıyız? Bu sorunun genel cevabı başka bir engel yoksa her zaman yüksek seviyede kalmaktır. Yani standart C kütüphanesi ile devam edebiliyorsak oradan devam etmeliyiz. Neden? Çünkü bir noktada programımızı başka bir işletim sistemine taşımak istersek işimiz çok daha kolay olacaktır. Ayrıca standart C kütüphanesinin fonksiyonları ve açıklamaları, benzer POSIX fonksiyonlarına çok daha basittir. Fakat standart C fonksiyonları daha az kapsamlıdır ve bazı durumlarda yetersiz gelebilmektedir. İşte bu noktada POSIX fonksiyonlarına geçmek daha doğru olacaktır. Ne demişler: Premature optimization is the root of all evil. [4]
Peki, POSIX deyip durduk. Nedir bu? Yenilir mi içilir mi? Sonraki kısımlarda bunu aktarmaya çalışacağım.
Öneriler ve Kaynaklar¶
Why is there a Linux kernel policy to never break user space?
https://yarchive.net/comp/linux/gcc_vs_kernel_stability.html